

|
|
学习Spark (๑• . •๑)
介绍
Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。Spark允许用户将数据加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法
Spark也支持伪分布式(pseudo-distributed)本地模式,不过通常只用于开发或测试时以本机文件系统取代分布式存储系统。在这样的情况下,Spark仅在一台机器上使用每个CPU核心运行程序。
Apache Spark™ is a unified analytics engine for large-scale data processing.
优势
- 首先,Spark为我们提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
- Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。
- Spark让开发者可以快速的用Java、Scala或Python编写程序。它本身自带了一个超过80个高阶操作符集合。而且还可以用它在shell中以交互式地查询数据。
- 除了Map和Reduce操作之外,它还支持SQL查询,流数据,机器学习和图表数据处理。开发者可以在一个数据管道用例中单独使用某一能力或者将这些能力结合在一起使用。
亲身体会
经过这两周的折腾,总算是在本地环境下完成了第一个spark项目,完成十万级文本分词和去重,速度还是挺快的,从读取数据、处理数据、再到保存数据,大概花了十分钟左右。这里操作的数据库都是MongoDB,因为爬虫爬取的数据都是直接保存到Mongo。
之后再增加数据量,达到四千多万,读取数据花了8分钟,下图是正在处理和保存数据的Spark UI。
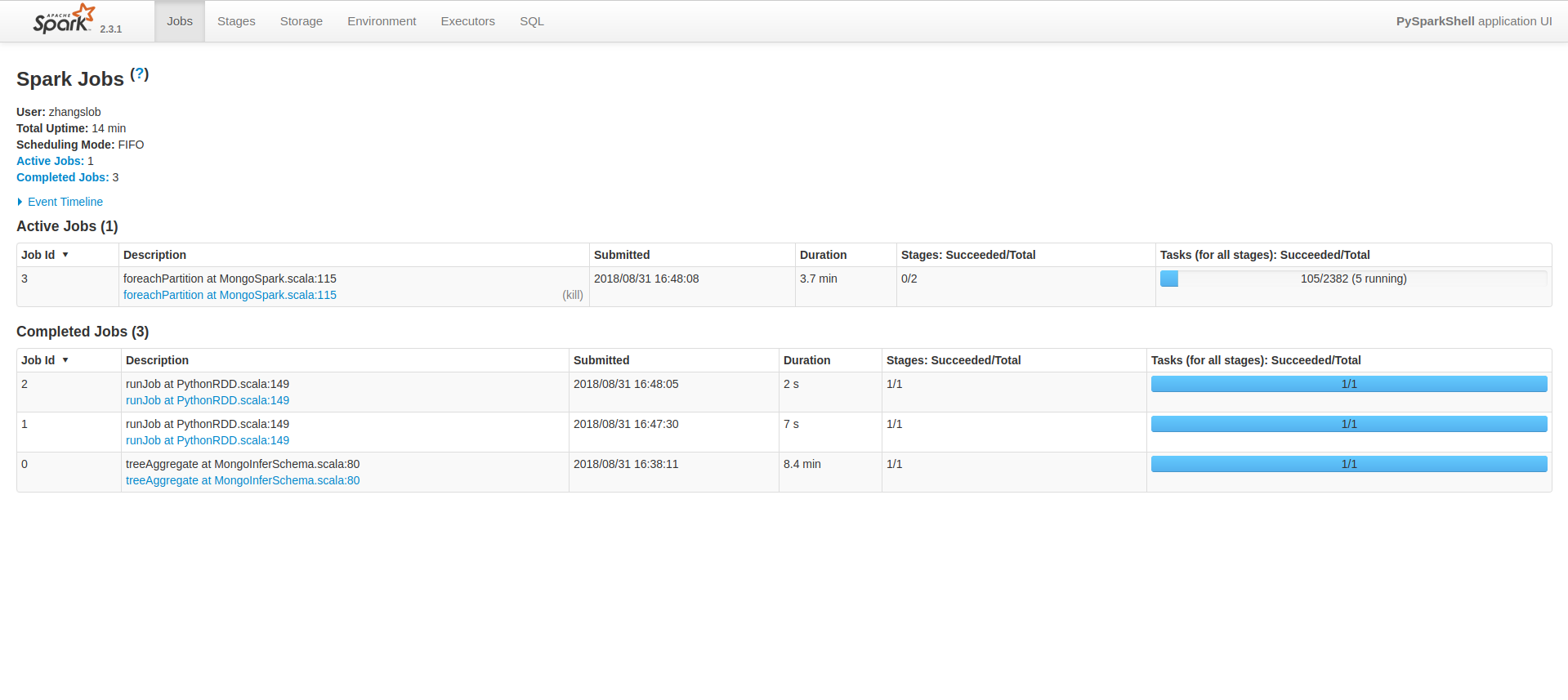
以前处理数据会使用pandas,数据会保存在内存中,数据量过大就会崩了,这也是为什么要使用分布式计算的原因。没有做过横向对比,暂时还不知道有多大差别。
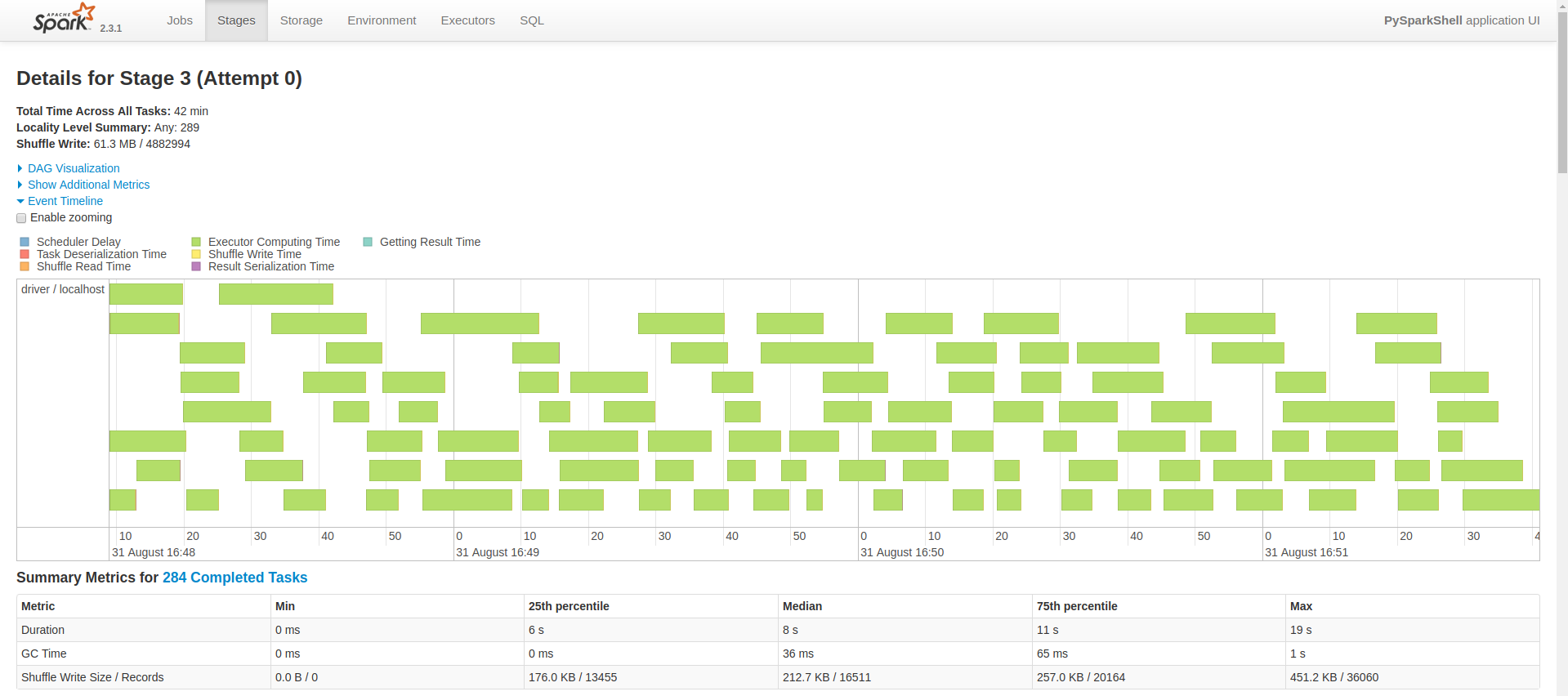
最后花了1.3h,本地处理完了四千多万数据,CPU和内存都要炸了,看来以后计算部分还是要搭集群。
学习计划
我在Github上开了一个仓库,记录所学,地址在这:learning-spark
刚开始使用的语言还是Python,目标是学Scala,看了些基础语法,和Python挺类似的,以后多写写,维持这个项目,记录各种坑。
ok,BB了这么多,下一篇就要开始真正的代码实战了。
