

|
|
深度学习 (๑• . •๑)
神经网络定义
人工神经网络,简称神经网络,在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
为了描述神经网络,我们先从最简单的神经网络讲起,这个神经网络仅由一个“神经元”构成,以下即是这个“神经元”的图示:

这个“神经元”是一个以 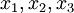 及截距
及截距 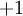 为输入值的运算单元,其输出为
为输入值的运算单元,其输出为 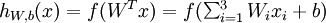 ,其中函数
,其中函数  被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数
被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数 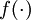

可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)。

神经网络模型
所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:

我们用 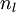 来表示网络的层数,本例中
来表示网络的层数,本例中 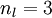 ,我们将第
,我们将第  层记为
层记为 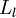 ,于是
,于是 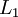 是输入层,输出层是
是输入层,输出层是 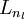 。本例神经网络有参数
。本例神经网络有参数 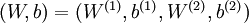 ,其中
,其中 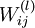 (下面的式子中用到)是第 层第
(下面的式子中用到)是第 层第  单元与第
单元与第 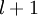 层第
层第  单元之间的联接参数(其实就是连接线上的权重,注意标号顺序),
单元之间的联接参数(其实就是连接线上的权重,注意标号顺序), 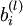 是第 层第 单元的偏置项。因此在本例中,
是第 层第 单元的偏置项。因此在本例中, 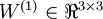 ,
, 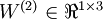 。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用
。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用 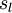 表示第 层的节点数(偏置单元不计在内)。
表示第 层的节点数(偏置单元不计在内)。
Keras实战
使用keras实现如下网络结构, 并训练模型:

使用场景:
输入值(x1,x2,x3)代表人的身高体重和年龄, 输出值(y1,y2)
|
|
创建模型
|
|
编译模型
需要指定优化器和损失函数:
|
|
训练模型
|
|
|
|
进行预测
|
|
|
|
关键词解释
- input_dim: 输入的维度数
- kernel_initializer: 数值初始化方法, 通常是正太分布
- batch_size: 一次训练中, 样本数据被分割成多个小份, 每一小份包含的样本数叫做batch_size
- epochs: 如果说将所有数据训练一次叫做一轮的话。epochs决定了总共进行几轮训练。
- optimizer: 优化器, 可以理解为求梯度的方法
- loss: 损失函数, 可以理解为用于衡量估计值和观察值之间的差距, 差距越小, loss越小
- metrics: 类似loss, 只是metrics不参与梯度计算, 只是一个衡量算法准确性的指标, 分类模型就用accuracy