
|
|
了解下redis的更多用法
SCAN
有时候需要从 Redis 实例成千上万的 key 中找出特定前缀的 key 列表来手动处理数据,可能是修改它的值,也可能是删除 key。这里就有一个问题,如何从海量的 key 中找出满足特定前缀的 key 列表来?
Redis 提供了一个简单暴力的指令 keys 用来列出所有满足特定正则字符串规则的 key。
|
|
这个指令使用非常简单,提供一个简单的正则字符串即可,但是有很明显的两个缺点。
没有 offset、limit 参数,一次性吐出所有满足条件的 key,万一实例中有几百 w 个 key 满足条件,
当你看到满屏的字符串刷的没有尽头时,你就知道难受了。
keys 算法是遍历算法,复杂度是 O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,
所有读写 Redis 的其它的指令都会被延后甚至会超时报错,
因为 Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的 keys 指令执行完了才可以继续。
建议生产环境屏蔽keys命令
Redis 为了解决这个问题,它在 2.8 版本中加入了指令——scan。
scan 相比 keys 具备有以下特点:
- 复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程;
- 提供 limit 参数,可以控制每次返回结果的最大条数,limit 只是对增量式迭代命令的一种提示(hint),返回的结果可多可少;
- 同 keys 一样,它也提供模式匹配功能;
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
- 返回的结果可能会有重复,需要客户端去重复,这点非常重要;
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零
scan 基础使用
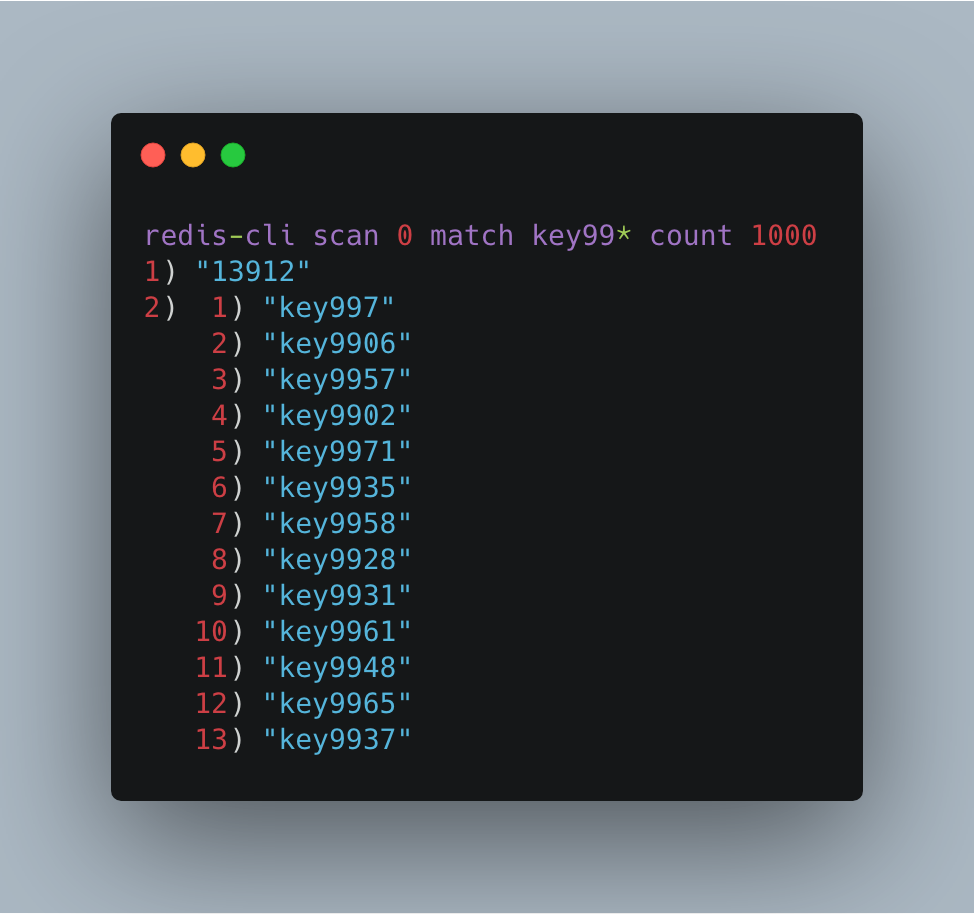
SCAN cursor [MATCH pattern] [COUNT count]
初始执行scan命令例如scan 0。SCAN命令是一个基于游标的迭代器。
这意味着命令每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
当SCAN命令的游标参数被设置为0时,服务器将开始一次新的迭代,而当redis服务器向用户返回值为0的游标时,
表示迭代已结束,这是唯一迭代结束的判定方式,而不能通过返回结果集是否为空判断迭代结束。
scan 参数提供了三个参数,第一个是 cursor 整数值,第二个是 key 的正则模式,第三个是遍历的 limit hint。
第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。
一直遍历到返回的 cursor 值为 0 时结束。
|
|
返回结果分为两个部分:第一部分即 1) 就是下一次迭代游标,第二部分即 2) 就是本次迭代结果集。
从上面的过程可以看到虽然提供的 limit 是 1000,但是返回的结果只有 10 个左右。
因为这个 limit 不是限定返回结果的数量,而是限定服务器单次遍历的字典槽位数量(约等于)。
如果将 limit 设置为 10,你会发现返回结果是空的,但是游标值不为零,意味着遍历还没结束。
|
|
更多的 scan 指令
scan 指令是一系列指令,除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。
zscan 遍历 zset 集合元素,
hscan 遍历 hash 字典的元素、
sscan 遍历 set 集合的元素。
注意点:
SSCAN 命令、 HSCAN 命令和 ZSCAN 命令的第一个参数总是一个数据库键。
而 SCAN 命令则不需要在第一个参数提供任何数据库键 —— 因为它迭代的是当前数据库中的所有数据库键。
大 key 扫描
有时候会因为业务人员使用不当,在 Redis 实例中会形成很大的对象,比如一个很大的 hash,一个很大的 zset 这都是经常出现的。
这样的对象对 Redis 的集群数据迁移带来了很大的问题,因为在集群环境下,如果某个 key 太大,会让数据导致迁移卡顿。
另外在内存分配上,如果一个 key 太大,那么当它需要扩容时,会一次性申请更大的一块内存,这也会导致卡顿。
如果这个大 key 被删除,内存会一次性回收,卡顿现象会再一次产生。
在平时的业务开发中,要尽量避免大 key 的产生。
如果你观察到 Redis 的内存大起大落,这极有可能是因为大 key 导致的,这时候你就需要定位出具体是那个 key,
进一步定位出具体的业务来源,然后再改进相关业务代码设计。
那如何定位大 key 呢?
为了避免对线上 Redis 带来卡顿,这就要用到 scan 指令,对于扫描出来的每一个 key,使用 type 指令获得 key 的类型,
然后使用相应数据结构的 size 或者 len 方法来得到它的大小,对于每一种类型,保留大小的前 N 名作为扫描结果展示出来。
上面这样的过程需要编写脚本,比较繁琐,不过 Redis 官方已经在 redis-cli 指令中提供了这样的扫描功能,我们可以直接拿来即用。
|
|
如果你担心这个指令会大幅抬升 Redis 的 ops 导致线上报警,还可以增加一个休眠参数。
|
|
上面这个指令每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长。
需要注意的是,这个bigkeys得到的最大,不一定是最大。
说明原因前,首先说明bigkeys的原理,非常简单,通过scan命令遍历,各种不同数据结构的key,分别通过不同的命令得到最大的key:
- 如果是string结构,通过strlen判断;
- 如果是list结构,通过llen判断;
- 如果是hash结构,通过hlen判断;
- 如果是set结构,通过scard判断;
- 如果是sorted set结构,通过zcard判断。
正因为这样的判断方式,虽然string结构肯定可以正确的筛选出最占用缓存,也可以说最大的key。
但是list不一定,例如,现在有两个list类型的key,分别是:numberlist–[0,1,2],stringlist–[“123456789123456789”],
由于通过llen判断,所以numberlist要大于stringlist。
而事实上stringlist更占用内存。其他三种数据结构hash,set,sorted set都会存在这个问题。
使用bigkeys一定要注意这一点。
slowlog命令
上面提到不能使用keys命令,如果就有开发这么做了呢,我们如何得知?
与其他任意存储系统例如mysql,mongodb可以查看慢日志一样,redis也可以,即通过命令slowlog。
用法如下
SLOWLOG subcommand [argument]
subcommand主要有:
- get,用法:slowlog get [argument],获取argument参数指定数量的慢日志。
- len,用法:slowlog len,总慢日志数量。
- reset,用法:slowlog reset,清空慢日志。
|
|
命令耗时超过多少才会保存到slowlog中,可以通过命令config set slowlog-log-slower-than 2000配置并且不需要重启redis。
注意:单位是微妙,2000微妙即2毫秒。
rename-command
为了防止把问题带到生产环境,我们可以通过配置文件重命名一些危险命令,
例如keys等一些高危命令。操作非常简单,
只需要在conf配置文件增加如下所示配置即可:
rename-command flushdb flushddbb
rename-command flushall flushallall
rename-command keys keysys