
这是崔斯特的第一百零三篇原创文章
![]()
最近在看一本书,《Flink原理、实战与性能优化》,记录下重点。
Flink是什么
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Flink优势
- 同时支持高吞吐、低延迟、高性能。Spark或Storm不能同时支持这三种。
- 支持事件事件(Event Time)概念。大多数框架仅支持系统时间(Process Time)。
- 支持有状态的计算。在流失计算中,将算子的中间计算结果保存在内存或磁盘中。
- 支持高度灵活的窗口(Window)操作。
- 基于轻量分布式快照(SnapShot)实现的容错。任务出现任务问题都可以从CheckPoints中自动恢复。
- 基于JVM实现独立的内存管理。Flink实现自身内存管理机制,通过序列化/反序列化将所有数据转化为二进制储存在内存中。
- Save Points(保存点)。Flink将任务执行的快照保存在储存介质上。(和第5点类似)。
Flink应用场景
- 实时智能推荐
- 复杂事件处理
- 实时欺诈检测
- 实时数仓与ETL
- 流数据处理
- 实时报表分析
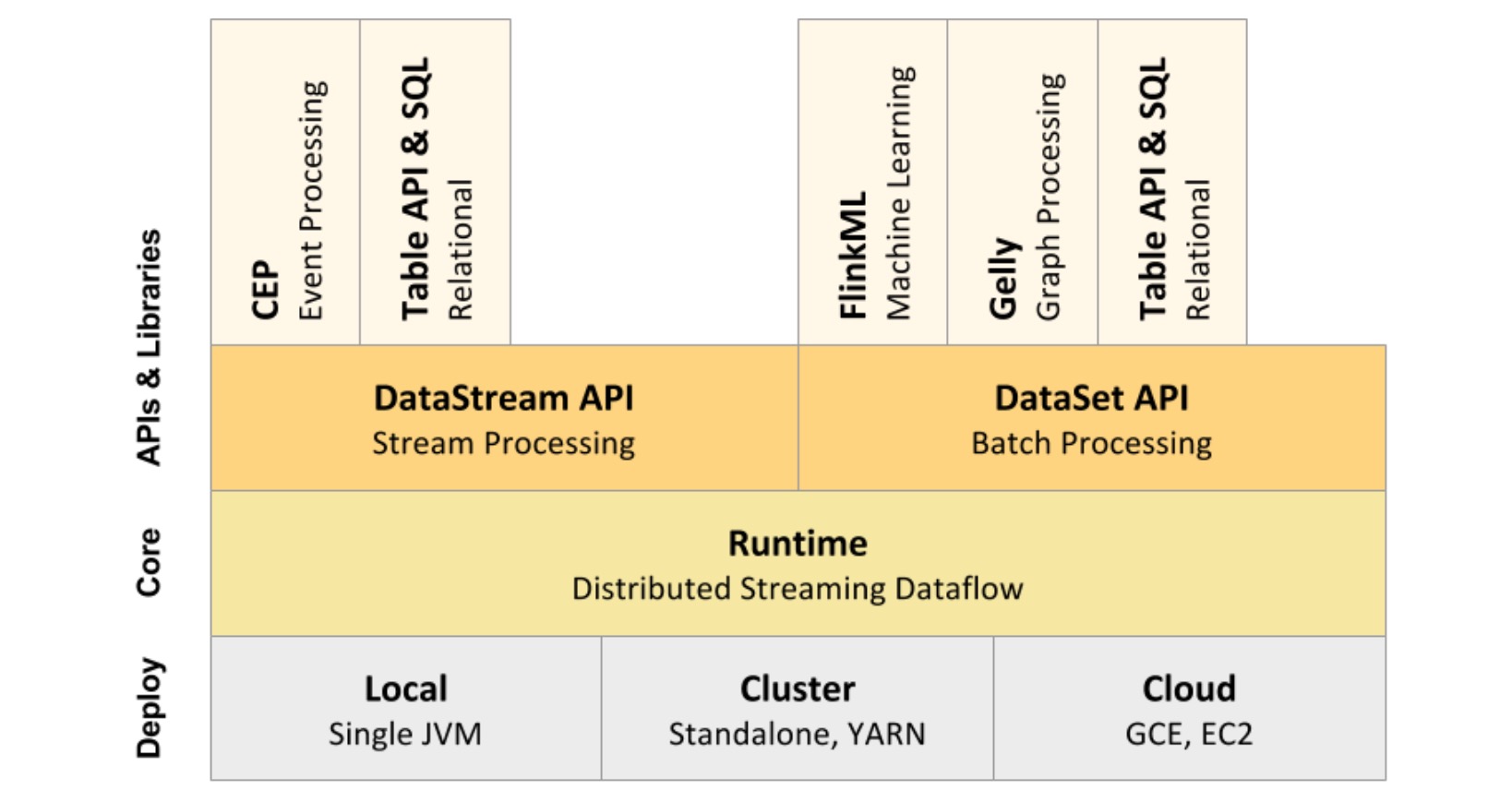
Flink组件栈
Flink作为一个软件堆栈,是一个分层系统。堆栈的不同层相互叠加,并提高它们接受的程序表示的抽象级别:
- 运行时层以JobGraph的形式接收程序。JobGraph是一个通用的并行数据流,其中包含使用和生成数据流的任意任务。
- DataStream API和DataSet API都通过单独的编译过程生成JobGraphs。数据集API使用优化器来确定程序的最佳计划,而DataStream API使用流构建器。
- JobGraph是根据Flink中可用的各种部署选项执行的(例如,本地、远程、Yarn等)
- Connector层所能对接的技术更是丰富多样,将不同类型、不同来源的数据介入到Flink组件栈中。
Flink架构图
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
- Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
- JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
- TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
可以看到 Flink 的任务调度是多线程模型,并且不同Job/Task混合在一个 TaskManager 进程中。虽然这种方式可以有效提高 CPU 利用率,但是个人不太喜欢这种设计,因为不仅缺乏资源隔离机制,同时也不方便调试。类似 Storm 的进程模型,一个JVM 中只跑该 Job 的 Tasks 实际应用中更为合理。
