
全站抓取的技巧
|
|
分布式全站爬虫——以”搜狗电视剧”为例
先看看robots协议
|
|
牛皮!
分析
打开一个具体的影视:http://kan.sogou.com/player/181171191/,网址中有具体数字ID,我们假设数字ID就是递增的,即从1开始,那么我们可以拼接url:
- http://kan.sogou.com/player/1/
- http://kan.sogou.com/player/2/
- http://kan.sogou.com/player/3/
- http://kan.sogou.com/player/4/
- …
有两个问题:
- ID上限是多少,我不可能永不止境的往上加吧
- 抓取效率问题,如果有10亿,那么我就需要发送10亿个HTTP请求,如果你开启了1000个线程,0.3秒能处理完一个ID,一天可以抓取:
1000 * 0.3 * 60 * 60 * 24= 25920000 个,需要约38天才能抓完,这肯定是不合乎要求的
针对这两个问题,可以用如下方法:
- 使用采样,比如我们确定间隔是1000,我们在1~1000中随机取数,在1001~2000中再随机取一个数,这样10亿数就被缩短为一百万了,这个数字就小多了
- 凭什么说上限是10亿呢,我们在真正爬虫之前还需要一次调研,调研的时候可以把间隔调大,比如5000,这次抓取只是为了评估ID分布范围,比如第一段是[1, 10000],第二段是[1000000, 9000000],最后一段是[10000000000, 10090000000]。确定ID分布范围后就可以在指定区间内采样抓取
代码
核心代码参考:generate_uid.py,该函数是主节点开启的一个线程,该线程会监控redis中爬虫start_urls队列,如果小于预期,调用生成器生成ID列表,加入到队列中,同时更新此时的ID到redis。
运行爬虫,命令是:scrapy crawl sougou -a master=True,日志样例如下:
|
|
分布式
这是MS设计,master负责去向队列里添加任务,slave负责消费。(这里的master同样有消费)
开启master只需要向启动命令添加额外参数,slave启动方式正常即可。
注意:master只能开启一个,否则会有重复任务,slave开启多少个取决于机器、网络、代理条件。
思考
这种全量抓取方式只适合ID是数字的,这种网站还挺多的,淘宝、京东、知乎、美团等等。这些ID并不是递增,而是分布在一块块区域,先宏观上调查出大体范围,再缩小ID间隔。
但是有些网站,比如优酷的:https://v.youku.com/v_show/id_XNDU4OTM3NzM0NA==.html,id明显就是混淆过的,想要全量抓取只能通过分类接口去抓。这个有时间再聊聊。
线程安全
我们想想,这样设计会不会有线程安全?
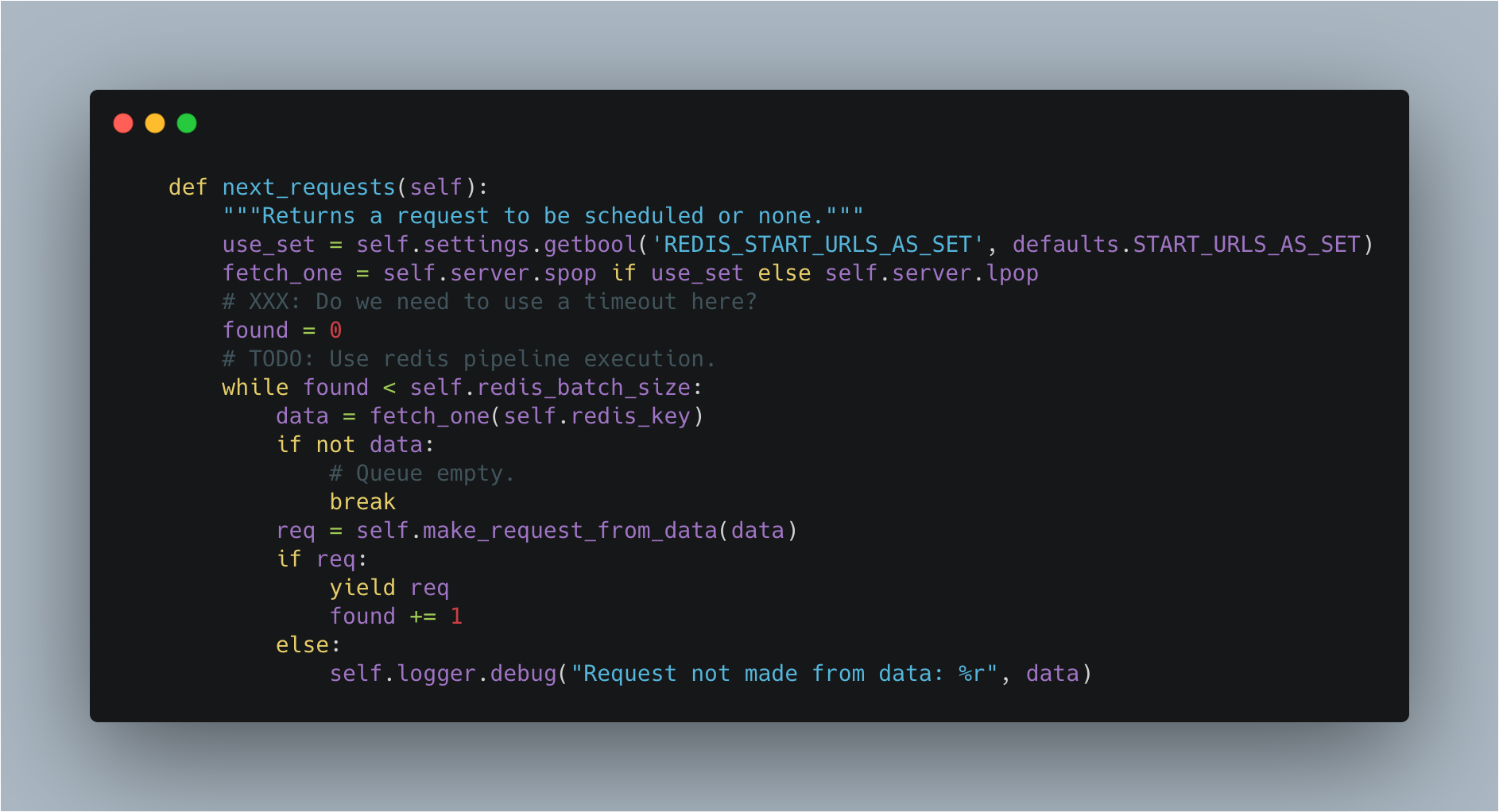
先看看slave端,对redis的操作只有一个就是获取redis里的id,我们看看代码,scrapy_redis.spiders.RedisMixin.next_requests
|
|
scrapy-redis使用使用list结构,所以这里我们用到的是lpop命令,多次去redis中获取request,直到found = self.redis_batch_size,每次从redis中获取request的数量如果没有设置,默认就是settings中的CONCURRENT_REQUESTS,一般就是16。
if self.redis_batch_size is None:
# TODO: Deprecate this setting (REDIS_START_URLS_BATCH_SIZE).
self.redis_batch_size = settings.getint(
'REDIS_START_URLS_BATCH_SIZE',
settings.getint('CONCURRENT_REQUESTS'),
)
每次从redis中获取到request后,会直接调用self.make_request_from_data(data)方法。作者在注释里也说到了这里的两个改进方法:
- Use timeout。redis的
lpop是阻塞操作,所以理论上需要加上超时 - Use redis pipeline。如果不了解的可以看看文档,Redis 管道(Pipelining),
有心可以去提个pr,以后就可以吹牛说自己是scrapy-redis的contributors了,有人已经行动了,read start_urls use redis pipeline
因为lpop是原子操作,任何时候只会有单一线程从redis中拿到request,所以在获取request这一步是线程安全的。对这块不熟悉的可以阅读Redis 和 I/O 多路复用
再看看master端,有两个redis操作,
- 查询spider种子数量,使用
llen - 如果数量小于预期,生成任务ID,使用
lpush插入数据
线程安全一般出现多线程之间的共享变量,这个场景下共享变量是什么,redis中的request列表吗,我仔细想了下,因为我们对redis的操作都保证原子性,并且插入的id保证不重复,所以不会出现问题。可以改进的地方,就是在master端使用redis pipeline操作。
欢迎交流想法。
实际应用
这两天看到一个新闻:
“卖空”研究公司Wolfpack Research今日在其网站上发布报告称,爱奇艺早在2018年IPO(首次公开招股)之前就存在欺诈行为,而且此后也一直在这样做。
该机构表示,我们估计爱奇艺将其2019年的营收夸大了约80―130亿元人民币(27%―44%),将其用户数量夸大了约42%―60%。
别的不说,就用户数,现在这个分布式爬虫就可以抓取用户数据。用户主页是:https://www.iqiyi.com/u/1416657079/feeds,也是数字的,同样可以使用采样的办法去抓取用户数据。